
[モンテカルロ木探索]
第12章 対局
モンテカルロ木探索の全体像
mcts_player.pyのgo()関数がやっていること

mcts_player.py
実際にプログラムを動作させる前に下記の修正を実施。
モデルロードの引数を追加
モデルをロードするPolicyValueResnet()に引数blocksを入れないとエラーが出るためPolicyValueResnet(blocks=5)に修正。5はこのモデルを学習したときと同じブロック数。
def isready(self):
# モデルをロード
if self.model is None:
self.model = PolicyValueResnet(blocks=5)CPU/GPU自動切り替え
IPアドレスでどのPCで動いているか判断させる。GPU使用するかどうかをフラグgpu_enで切り替える。ついでにモデルファイルのパスもフラグenvで切り替える。
# 環境設定
#-----------------------------
import socket
host = socket.gethostname()
# IPアドレスを取得
# google colab : ランダム
# iMac : xxxxxxxx
# Lenovo : yyyyyyyy
# env
# 0: google colab
# 1: iMac (no GPU)
# 2: Lenovo (no GPU)
# gpu_en
# 0: disable
# 1: enable
if host == 'xxxxxxxx':
env = 1
gpu_en = 0
elif host == 'yyyyyyyy':
env = 2
gpu_en = 0
else:
env = 0
gpu_en = 1
#-----------------------------importのところ
if gpu_en == 1:
from chainer import cuda, Variabledef init(self):
# モデルファイルのパス
if env == 0:
self.modelfile = '/content/drive/My Drive/・・・/python-dlshogi/model/model_policy_value_resnet'
elif env == 1:
self.modelfile = r'/Users/・・・/python-dlshogi/model/model_policy_value_resnet'
elif env == 2:
self.modelfile = r"C:\Users\・・・\python-dlshogi\model\model_policy_value_resnet"
self.model = None # モデルdef eval_node()
if gpu_en == 1:
x = Variable(cuda.to_gpu(np.array(eval_features, dtype=np.float32)))
elif gpu_en == 0:
x = np.array(eval_features, dtype=np.float32)
with chainer.no_backprop_mode():
y1, y2 = self.model(x)
if gpu_en == 1:
logits = cuda.to_cpu(y1.data)[0]
value = cuda.to_cpu(F.sigmoid(y2).data)[0]
elif gpu_en == 0:
logits = y1.data[0]
value = F.sigmoid(y2).data[0]def isready()
# モデルをロード
if self.model is None:
self.model = PolicyValueResnet(blocks=5)
if gpu_en == 1:
self.model.to_gpu()コマンドラインからテスト
開始局面でプログラムを実行してみた。7六歩が143回訪問、2六歩が77回訪問という結果。とりあえずよさそうである。

Google Colabでも実行できた。
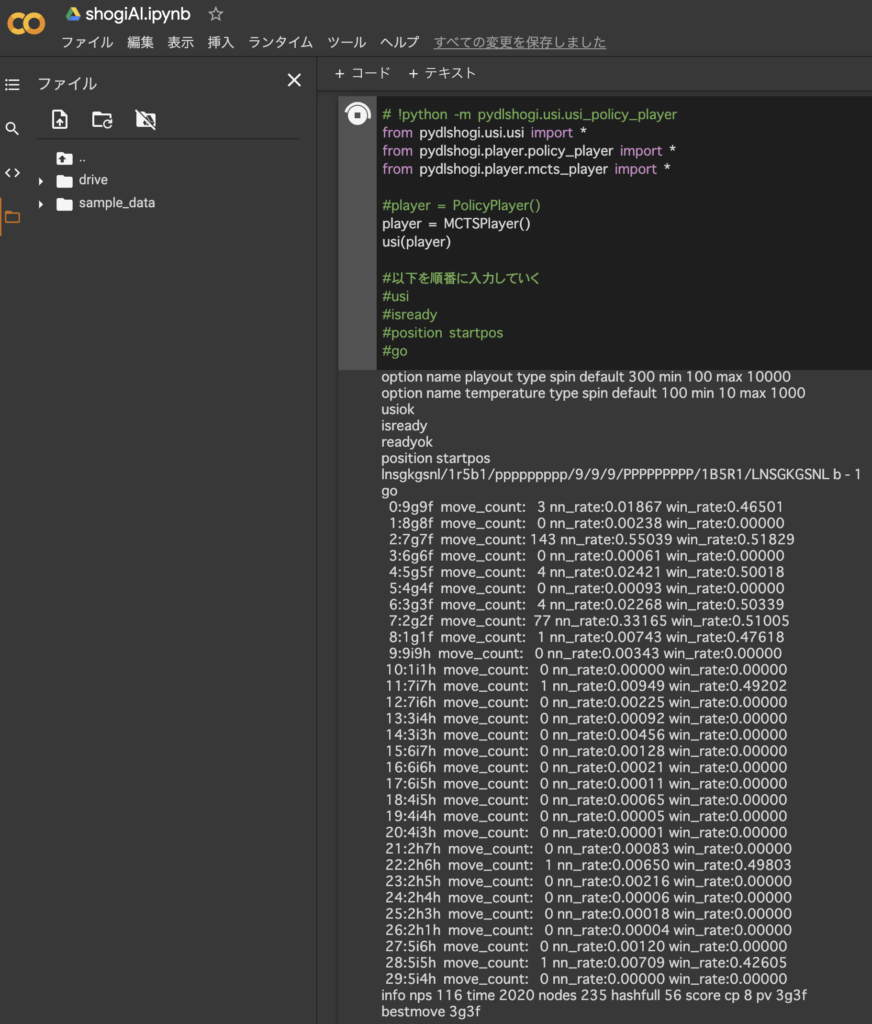
move_count : その指し手ノードの訪問回数
nnrate : 方策ネットワークの予測確率
win_rate : 指し手の平均勝率(=合計勝率/訪問回数)
nps : node/time
time : 1回のgo()に要した時間
nodes : 現ノードの訪問回数(current_node.move_count)
hashfull : node_hash配列とuct_node配列の占有率。4096要素中何要素使ったかを示す。100%占有していた場合を1000として表した数値。
score cp : 評価値
pv : 指し手の座標
GPUはCPUの2倍高速
上記結果より1回の実行あたりの所要時間はCPUは3524 ms、GPUは2020 msであった。よってGPU/CPU速度比は3524/2020=1.7。約2倍高速である。
現ノードの訪問回数(nodes)はGPUもCPUも235回と変わらない。単純に訪問1回あたりの速度がGPUの方が速いということがわかる。
探索打ち切りの効果
探索ごとにinterruption_check()という関数で探索を途中で打ち切るか判定している。探索回数は300回に設定しているが、残りの探索を全て次善手に費やしても最善手を超えられない場合は300回に達していなくても探索を打ち切るというものである。上記結果はnodes 235となっているので235回で打ち切られていることがわかる。
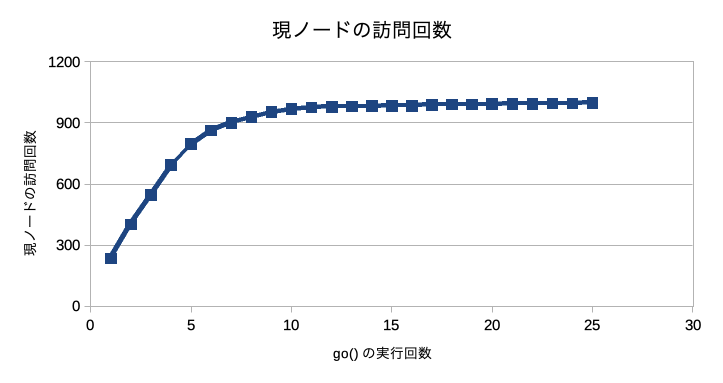
参考までにgo()を連続で実行して現ノードの訪問回数をプロットしてみた。go()の実行回数が増えるにつれ現ノードの訪問回数が増えなくなっていくことがわかる。go()の実行回数が増えるにつれ子ノードの訪問回数も増えていくから探索を打ち切るのが早くなっているのであろう。
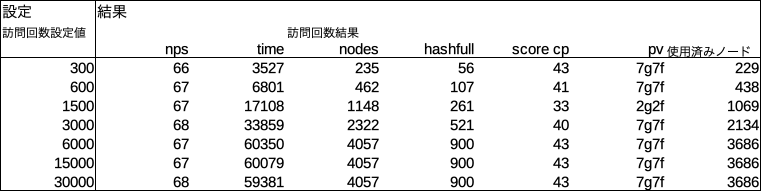
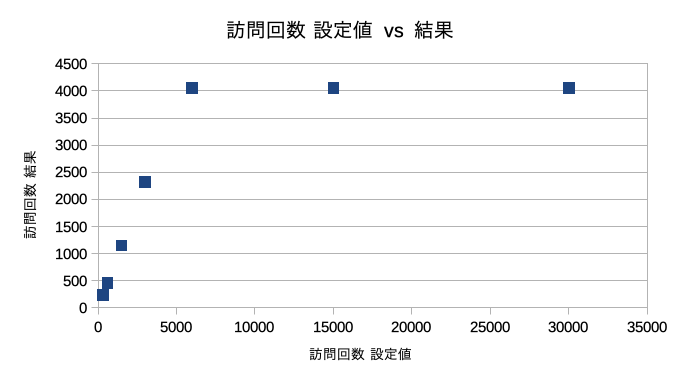
探索回数
探索回数によって現ノードの訪問回数がどうなるかを把握してみた。訪問回数設定値6000回以上で結果が4057回から増えなくなる。これはあくまで開始局面での結果である。局面によって結果は異なるであろう。
対局
自分(アマ初段) 対 第12章5のAI
方策ネットワーク&価値ネットワーク&モンテカルロ木探索 有り。並列化 無し。変な手を打つことが多く想像していたよりも弱かった。
終局図

コメント