
[モンテカルロ木探索]
第12章 全体感
モンテカルロ木探索の全体像
mcts_player.pyのgo()関数がやっていること

モンテカルロ木探索の骨子uct_search()
このメソッドはざっくり言うとUCB値が大きいノードを選択し勝率の合計を加算していくメソッド。理解がかなり難しかったので例を作成して理解した。例えば探索開始から3回目の探索までを下記のように行ったとする。
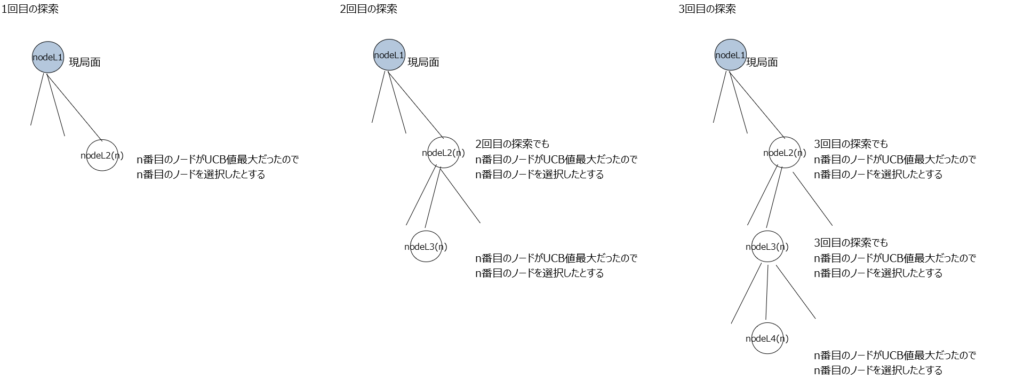
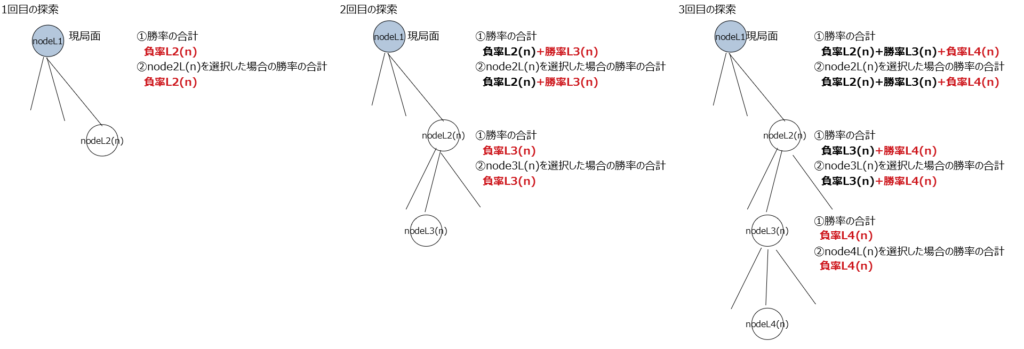
探索が行われるごとに各ノードが持つ変数にそのノード視点での勝率が加算される。
変数① 勝率の合計(変数名win):全ノード分の②の合計。(この例は①は②と同じ値になっているが各ノードがまだ1個しか探索していないから同じ値になっているだけで①と②は別の変数である。)
変数② node**を選択した場合の勝率の合計(変数名child_win)
他にも変数は有るが重要なのはこの①と②の2つ。価値ネットワークの予測勝率(変数名value_win)と①は別の変数であることに注意。
なお、この関数uct_search()では各ノードの訪問回数も記録している。この関数を抜けた後、go()関数の中では訪問回数が最大の手を最終的な指し手として選択することになる。また、②を訪問回数で割った値つまり平均勝率をその指し手の勝率として扱うことになる。それを念頭に置いておくと理解しやすくなる。
この例において変数の中身がどのように変化していくか時系列で追ってみた。
1回目の探索

2回目の探索
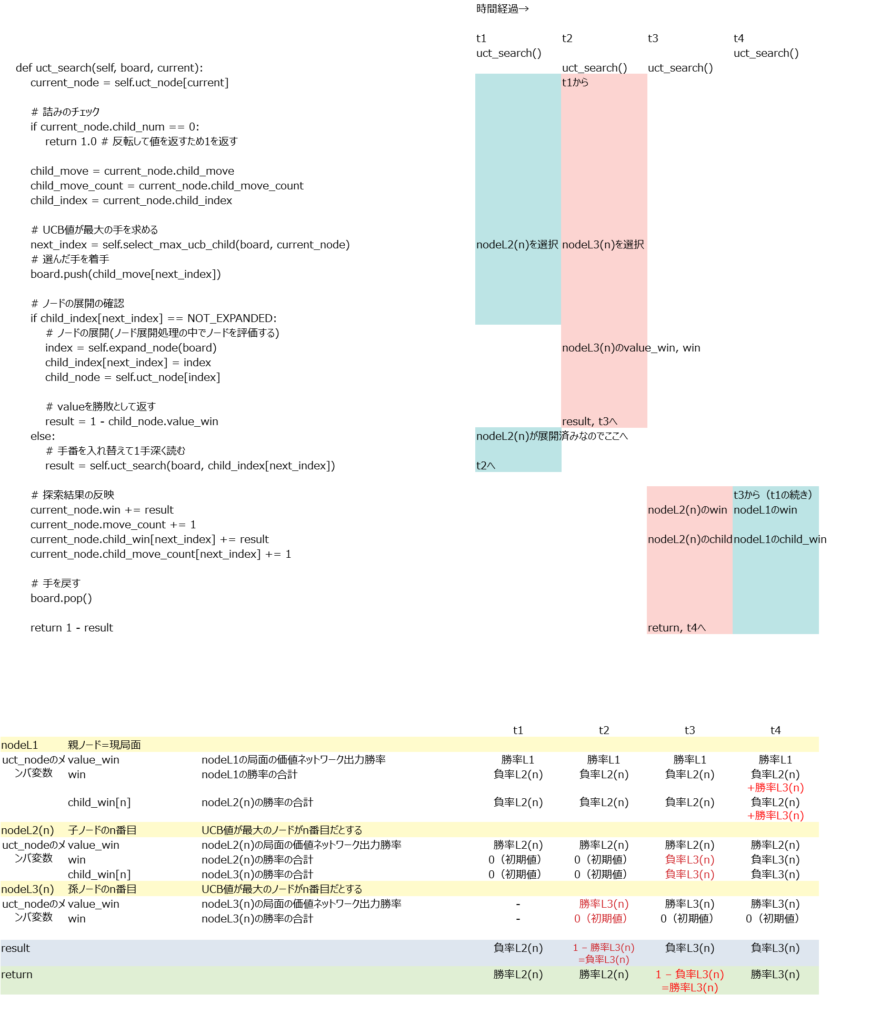
3回目の探索
ここまでやってやっと理解できた。単に自分の勝率と相手の負率(=自分の勝率)を積算しているだけである。

コメント