
[価値ネットワーク]
第11章
学習テクニック
普通の学習
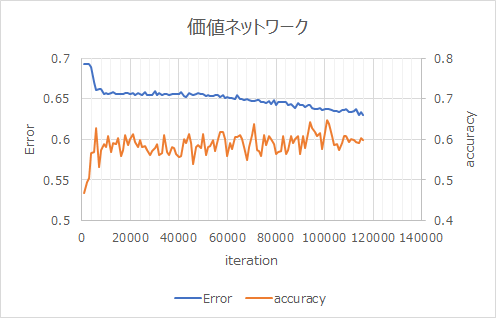
第10章の価値ネットワークの学習結果。
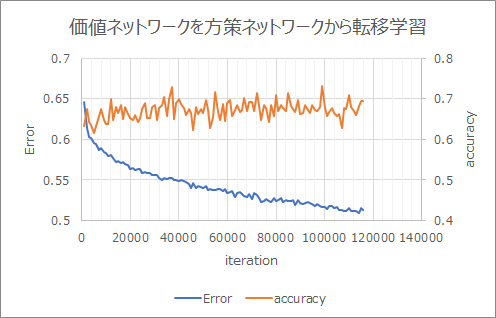
転移学習
方策ネットワークの学習結果を転移させて学習。Errorが低くaccuracyが高くなった。
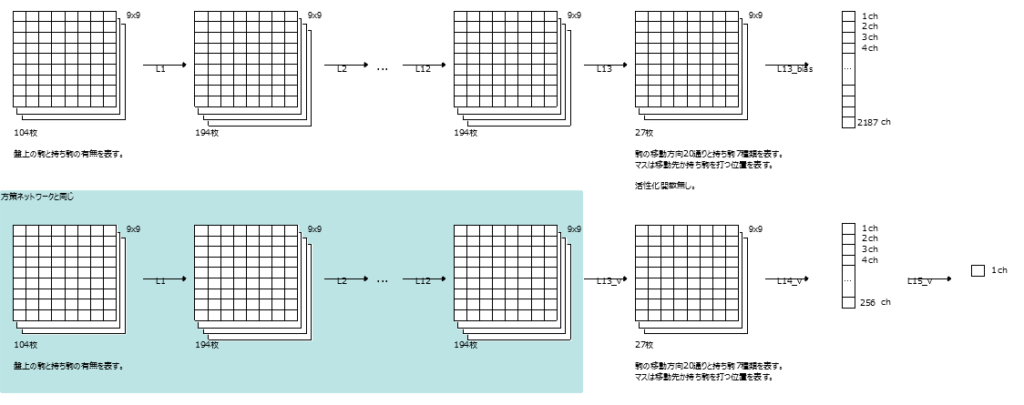
マルチタスク学習
上段が第7章の方策ネットワーク
下段が第10章の価値ネットワーク
水色のところが同じなので共通化するというのがマルチタスク学習の考え方。
水色を共通化するとこうなる。
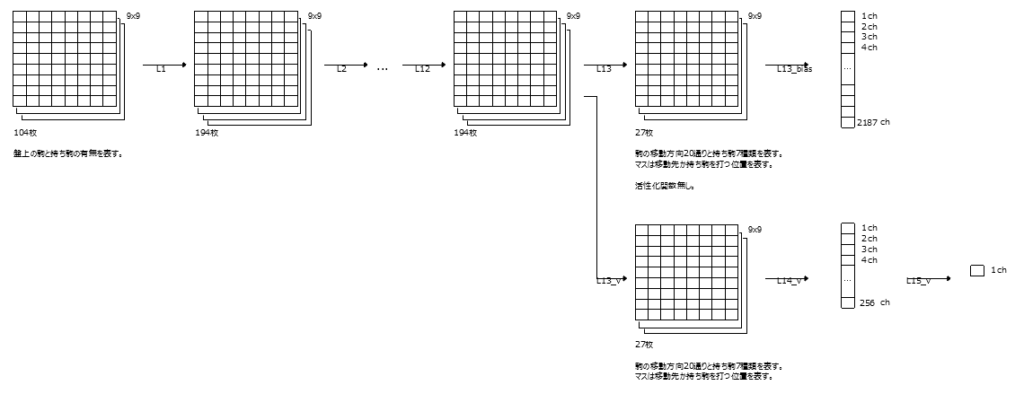
方策と価値が同時に学習できる。accuracyも良い。
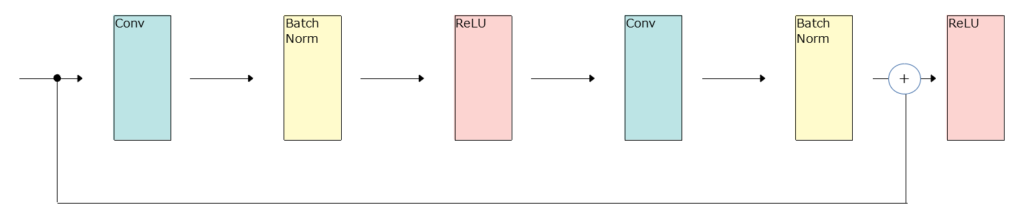
Residual Network
ResNetという構成が良いらしい。なぜResNetが良いのか自分はよく理解できていないが研究が進んでいるらしい。
ResNetの1ブロック
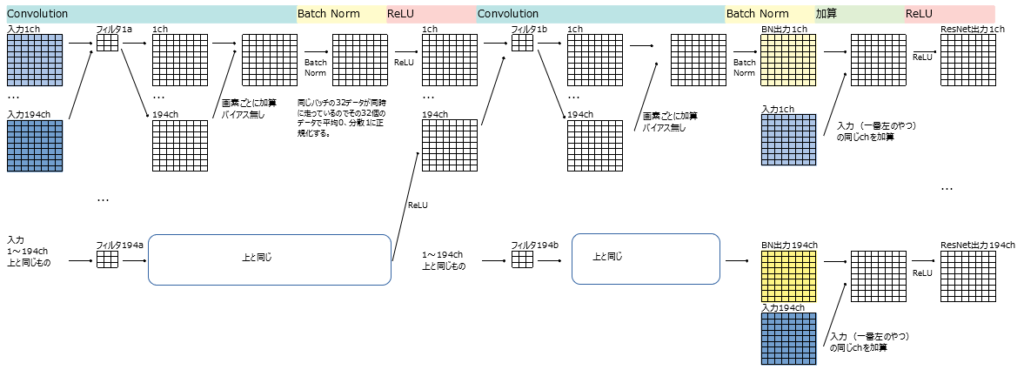
ResNetの1ブロックの詳細
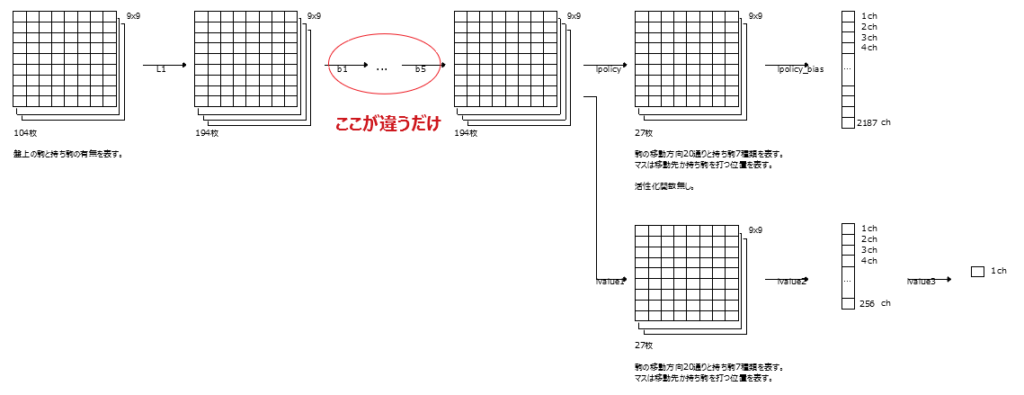
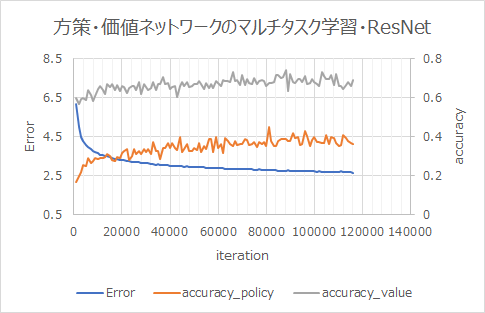
このResNetブロックを5個つなげてマルチタスク学習のL2~L12と入れ替える。
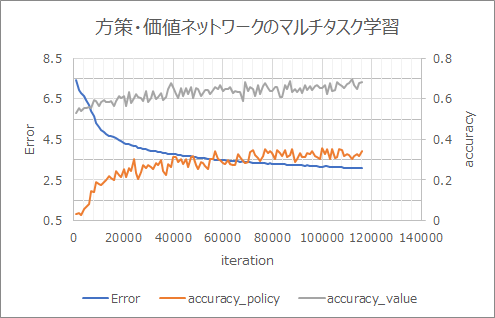
学習結果
ResNet無しのときより早く学習が進んでいる。
policy_value_resnet.py
x + h2というのはxとh2を「要素ごとに」足す操作。(実際に値をprintしてみたらそうなっていた)
def __call__(self, x):
h1 = F.relu(self.bn1(self.conv1(x)))
h2 = self.bn2(self.conv2(h1))
return F.relu(x + h2)h = self[‘b{}’.format(i)](h)
この書き方でself.bi(h)という意味になる。
for i in range(1, self.blocks + 1):
h = self['b{}'.format(i)](h) #!/usr/bin/env python3
# -*- coding: utf-8 -*-
from chainer import Chain
import chainer.functions as F
import chainer.links as L
from pydlshogi.common import *
ch = 192
fcl = 256
class Block(Chain):
def __init__(self):
super(Block, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn1 = L.BatchNormalization(ch)
self.conv2 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn2 = L.BatchNormalization(ch)
def __call__(self, x):
h1 = F.relu(self.bn1(self.conv1(x)))
h2 = self.bn2(self.conv2(h1))
return F.relu(x + h2)
# x + h2は値をprintして確認したらxとh2を要素ごとに足していた。つまりxもh2もx+h2も194要素。
# 第1感は388要素になったりしないか心配になったため確認してみたが、F.reluの中だと要素ごとに加算されるということか。
class PolicyValueResnet(Chain):
def __init__(self, blocks):
super(PolicyValueResnet, self).__init__()
self.blocks = blocks
with self.init_scope():
self.l1 = L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
for i in range(1, blocks + 1):
self.add_link('b{}'.format(i), Block()) # 第1引数が名前、第2引数がクラス
# policy network
self.lpolicy = L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.lpolicy_bias = L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
# value network
self.lvalue1 = L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1)
self.lvalue2 = L.Linear(9*9*MOVE_DIRECTION_LABEL_NUM, fcl)
self.lvalue3 = L.Linear(fcl, 1)
def __call__(self, x):
h = F.relu(self.l1(x))
for i in range(1, self.blocks + 1):
h = self['b{}'.format(i)](h) # この書き方でself.bいくつになる。
# policy network
h_policy = self.lpolicy(h)
policy = self.lpolicy_bias(F.reshape(h_policy, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
# value network
h_value = F.relu(self.lvalue1(h))
h_value = F.relu(self.lvalue2(h_value))
value = self.lvalue3(h_value)
return policy, value

コメント