
[方策ネットワーク]
第9章
学習テクニック
SGD
$$W^{t+1} ← W^t-lr\frac{∂E(W^t)}{∂W^t}$$
lr = 0.01
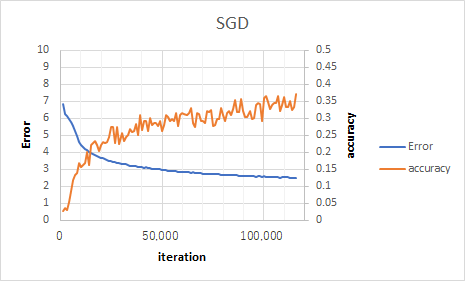
Momentum SGD
$$W^{t+1} ← W^t-lr\frac{∂E(W^t)}{∂W^t}+αΔW^t$$
lr = 0.01
途中で学習が止まった。lrが大きすぎたか。(本ではlr = 0.005にしている。)
Batch Normalization
lr = 0.01
Batch Normalizationすることでaccuracyが向上した。
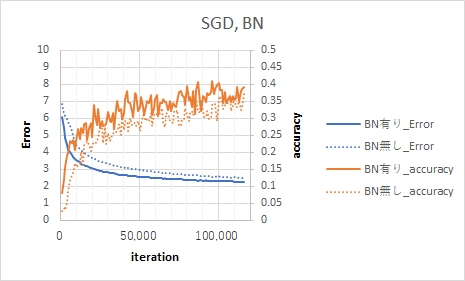
Batch Normalizationの詳細は本には書いていないので下記記事を見て勉強した。
・バッチノームは、ミニバッチごと同一チャネルごとで、活性化関数を通す前の値を平均0,分散1に正規化するもの。
・バッチノームで改善する理由は不明。

【GIF】初心者のためのCNNからバッチノーマライゼーションとその仲間たちまでの解説 - Qiita
CNNからバッチノーマライゼーションとその仲間たちまでを図で解説!ディープラーニングが流行するきっかけとなった分野は画像認識と言っても過言ではないでしょう。実際にディープラーニング流行の火付け役…
qiita.com
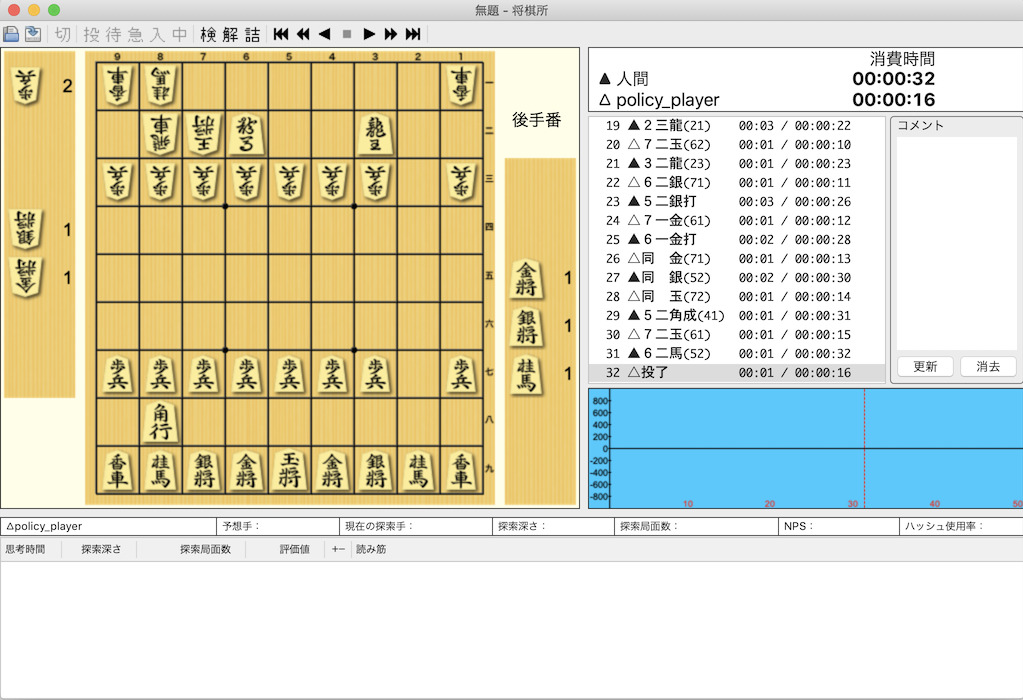
バッチノームを導入したAIで対局してみた。バッチノーム弱すぎ。
終局図

コメント