
[方策ネットワーク]
第8章
戦略
グリーディー戦略
貪欲法。単純にニューラルネットワークの出力値の最も高い手を選ぶ方法。logitsとはニューラルネットワーク出力段の活性化関数を通す前の値。
def greedy(logits): # 引数に指定したリストの要素のうち、最大値の要素のインデックスを返す
# logitsとはニューラルネットワークでは活性化関数を通す前の値のこと
return np.argmax(logits)ソフトマックス戦略
温度という係数で確率が変わるっぽい。
def boltzmann(logits, temperature):
logits /= temperature # a /= b は a = a / b の意味
logits -= logits.max() # a -= b は a = a - b の意味。 マイナスの値になる。最大値は0。
probabilities = np.exp(logits) # x =< 0 のexp関数
probabilities /= probabilities.sum()
return np.random.choice(len(logits), p=probabilities) # choice(i, p=b)は0~i-1までの数値をbの確率でランダムに返すフロー図

簡単な例として出力が5個(出力1が-0.2、出力2が0.3、出力3が0.5、出力4が0、出力5が-0.6)の場合のexp出力までの処理を図示する。温度は1とする。
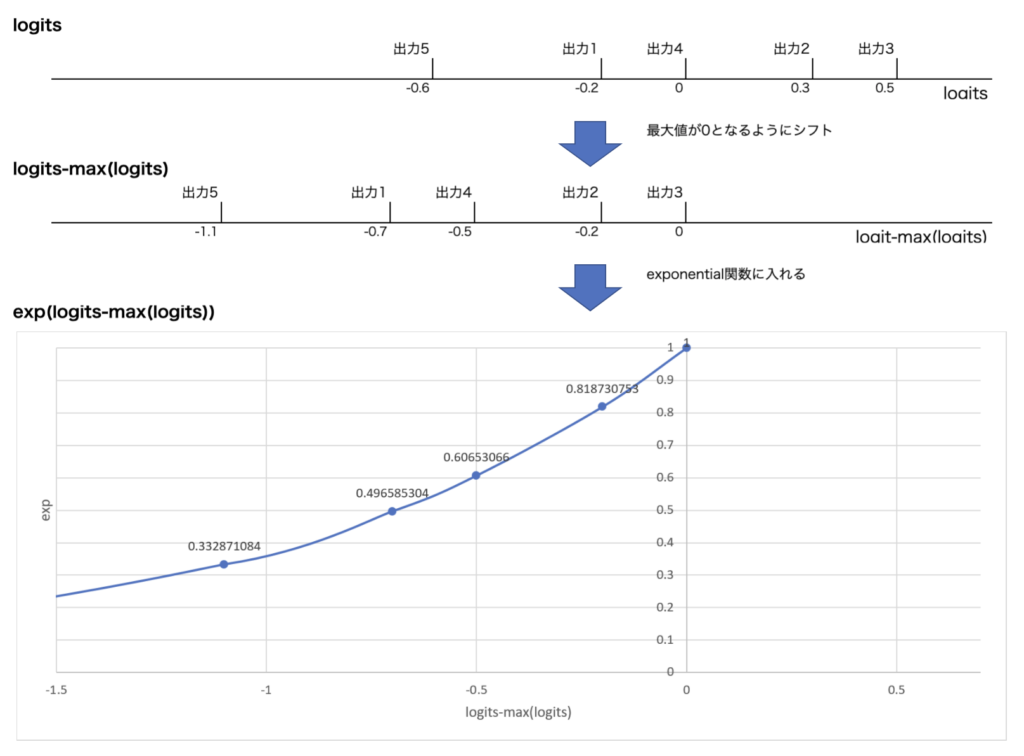
温度を設定すると温度が小さいほど各出力の大きさが近くなる。つまり、温度が小さいほど指し手の確率が均等になっていく。
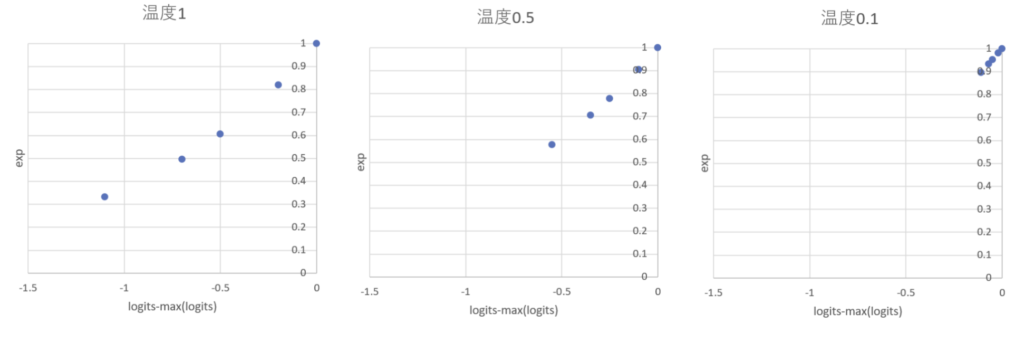
第8章では最後にランダム性を持たせる処理をしている。ランダム性を持ちつつ確率が高い手ほど選ばれやすい。第12章ではこの処理はしていない。よく理解できていないが使い方に合わせているのか。
return np.random.choice(len(logits), p=probabilities) # choice(i, p=b)は0~i-1までの数値をbの確率でランダムに返す
コメント